Research
Real-time control of avatars and robots
During the 1st year of the project, we are developping a research platform to control in real-time (personalized) avatars and/or robots from the movements of anyone standing in front of the sensors. At the sensor level, we are using Kinect sensors and Tobii and FaceLab eyetrackers. Articulatory and rigid motion parameters are derived from the RGB-D images provided by the Kinect sensor. Finally, online manipulation of selected parameters can be applied before animating the avatars/robots.
Selected publication
- What makes human so different? Analysis of human-humanoid robot interaction with a super Wizard of Oz platform
Face detection based on PhotoPlethysmoGraphy (PPG)
We developed a method to detect faces based on the variations in reflected light due to vascular blood volume pulse. Whereas most methods use feature detection frame by frame, this method is based on the fact that face is part of a living body. We measure the variations in reflected light due to vascular blood volume pulse in various ROIs and detect which ROI(s) represent(s) a living body part.
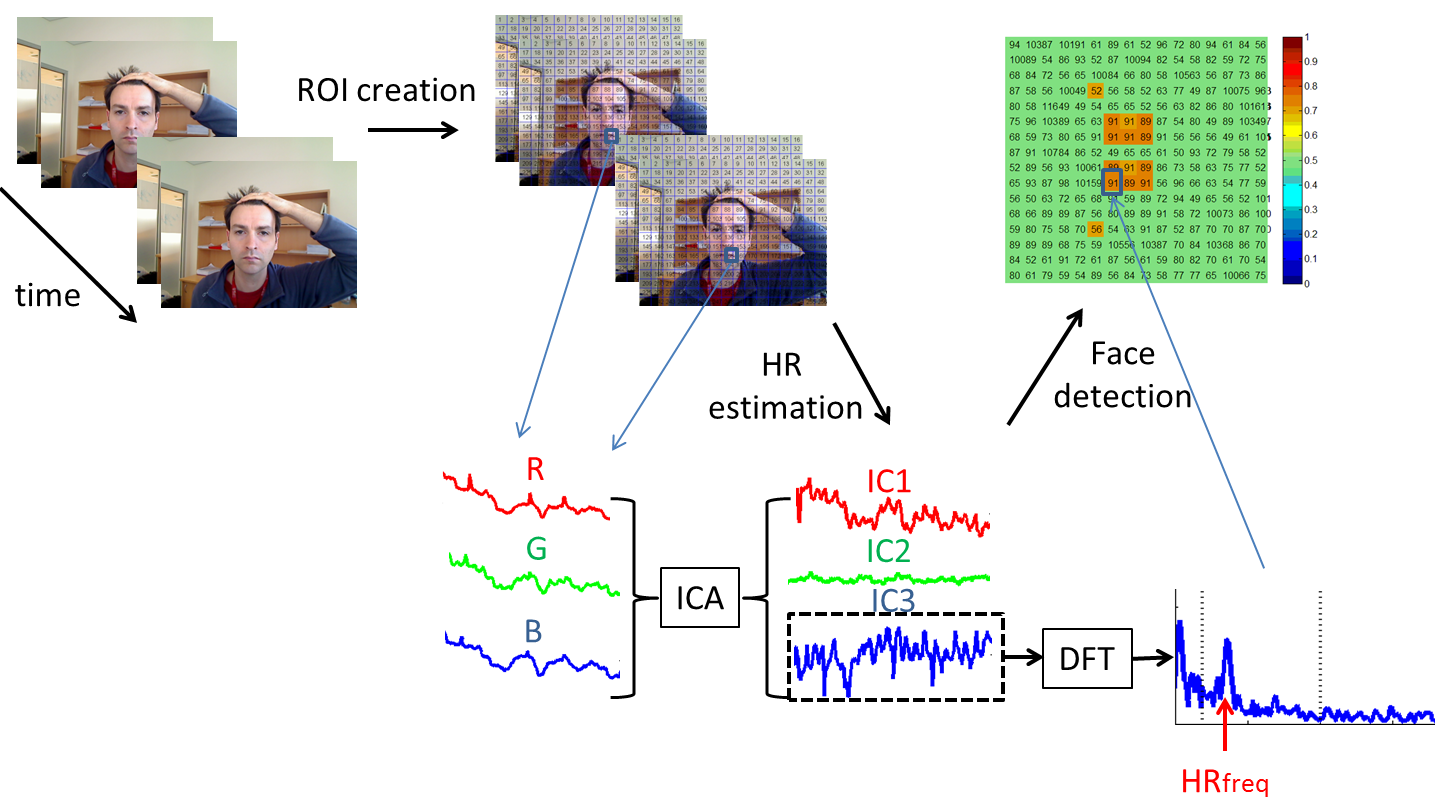 |
Images from a video stream are captured and then sliced into small ROIs. For each ROI, the average value of the Blue, Red and Green channels are computed. An ICA is applied to these signals to separate a 'common' heart rate (HR) signal. The ROIs presenting a significant HR signal are selected to be representative of a living body part. |
Source code
The Matlab functions can be found here.
Selected publication
- Face detection method based on photoplethysmography
Realistic tongue model for avatars
We developed a realistic tongue model using electromagnetic articulography (EMA) data and a generic 3D tongue mesh. Whereas the original tongue model was driven by a set of keyframes and linear interpolations between them, the new model is driven by continuous articulatory parameters controlling specific tongue gestures (tongue front-back, tongue flattening-bunching, tongue tip vertical and tongue tip horizontal movements).
Selected publication
- Multimodal Speech Animation from Electromagnetic Articulography Data